

Crisis of Replicability – “Ball Don’t Lie” (Part I)
This is the first post in a two part series. To skip ahead, here is Part II
Former NBA basketball player Rasheed Wallace was a polarizing figure. A cerebral big man with an even bigger temper, he’s remembered mostly for berating referees. Those that followed his ref-trolling know that after receiving a shooting foul that he disagreed with, he would often yell “ball don’t lie” when the opposing player missed his ensuing free throw(s). His glib point was that a bad call won’t be unjustly rewarded with points by the basketball gods.
Ball don’t lie epitomizes a massive problem in scientific research: the crisis of replicability. This crisis refers to the inability for scientific research – standardized through the Random Control Trial method – to reproduce in practice. A determination of the validity may be had in an academic journal, but once the study is let out in the real world, only the truth speaks. What we’ve found is an inability to reproduce findings. This crisis touches all disciplines where the scientific method is implemented: biomedical research, econometrics, and quantitative investing to name a few.
In a world of information deluge and ever-complex areas of study, the public leans on expertise to guide our collective knowledge from important fields such as economics, public health, business, and government. This knowledge leads to recommendations that ultimately shape behavior, policy, and society. To highlight the state of discord in research, Stanford Professor John Ioannidis produced the following chart (made into a snazzy graphic by vox) in a study highlighting contradictory findings across academic studies focused on the carcinogenesis of common food. The chart highlights the range of contradictory outcomes found in common foods across various peer-reviewed studies:
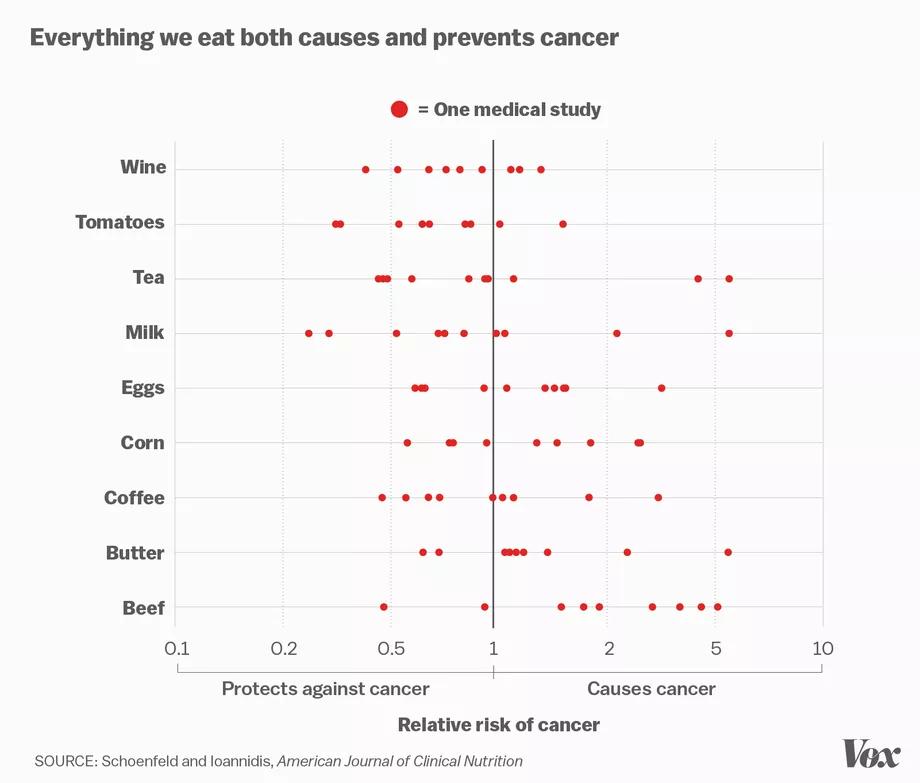

Ioannidis has made huge strides in bringing this problem to light. His piece “Why Most Published Research Findings Are False,” is an excellent primer to the problem, and its title summarizes the audacity of his position. He lays out the case for endemic problems in how the scientific community approaches publication, which ultimately results in a lack of replication of large portions of findings. If you haven’t read the piece, I strongly recommend a stab. While a bit theoretical, his writing is far more succinct and acute than mine. If that proves to be a bit wonky, the rest of the piece will frame the most salient bits. Part two of this blog series will apply his lens of critique to the practice of quantitative finance.
The two overarching concerns with replicability fall in Bias and Multiplicity of Testing (italics are direct quotes):
Bias – Bias can entail manipulation in the analysis or reporting of findings. Selective or distorted reporting is a typical form of such bias.
Bias is a huge problem in even the most well-intentioned peer-reviewed research. This is largely due to the principal / agent problem between researcher and peer-reviewer. Researchers are incentivized to find compelling results given the resources and time applied to conducting the tests. Reviewers (as principals) are less informed than the researchers (as agents) given the amount of time conducted by the researchers and their direct role shaping and disseminating the findings. While advances in technology have made measurements more precise, this may have lulled us into a false belief of accuracy. Bias rears its ugly head in several ways including:
- the specific calibration of the study which hides the robustness of the findings (usually behind a p-value or t-stat)
- burying arms of the study that proved inconclusive and reporting those that confirm one’s priors
- reverse bias, where true findings are buried due to their inconvenience
Multiplicity of Testing –the prevailing mentality until now has been to focus on isolated discoveries by single teams and interpret research experiments in isolation
Imagine you had 100 teams across the world unknowingly testing the same research question. Assuming best-efforts across all teams toward “gold standards”, there is a large probability that some fraction of these studies finds a statistically significant outcome, simply due to the increased number of tests. This is an insidious form of p-hacking for the aggregate finding, because any one of those research teams that finds significance will think they hit paydirt, and without coordination across teams, the urge to publish and land plaudits may override any inclination to confirm validity. The onus is then on the community to retort findings and that involves confrontation and thus politics. Further, the race to publish imparts game theory dynamics discussed later in the piece. This problem increases in study designs that are underpowered, which are endemic to certain forms of research.
Bias and Multiplicity of Testing can be unpacked through a few generic corollaries:

Corollaries
- The smaller the studies conducted in a scientific field, the less likely the research findings are to be true.
- Studies that can span thousands of samples increase power, reducing the impact of noise and the knock-on effects of spurious findings / multiplicity / noise conflation / susceptibility to bias
- The smaller the effect sizes in a scientific field, the less likely the research findings are to be true
- Minor efficacy exacerbates all the above and is susceptible to fiddling in order to find worthy findings. A classic example is in biomedical research, where the bar for a therapeutics’ commercial approval need only be an increase in efficacy versus the status quo, rather than a “significant” increase. This creates perverse incentives for the race to approve therapeutics with effectively similar efficacy, as the new drug can leapfrog patent expiries and exact higher price points (and profits).
- The greater the number and the lesser the selection of tested relationships in a scientific field, the less likely the research findings are to be true
- Perhaps the key point here is the “lesser the selection of tested relationships.” This is particularly pernicious in backtesting, where throwing a nearly infinite number of testable relationships will find some spaghetti that sticks to the wall. That doesn’t mean you’ll want to eat it.
- The greater the flexibility in designs, definitions, outcomes, and analytical modes in a scientific field, the less likely the research findings are to be true
- Going back to the principal/agent issues at play with research, a reader doesn’t know whether the calibration choices of the experiment were done for benign or nefarious reasons. The lines often blur. Imagine a study that winsorizes the tails of results and finds efficacy but has the opposite effect when that winsorization is removed. Without intiminate knowledge about that methodological choice, the reader is left to rust that the choice is meaningful and done in good faith. More often than not, these rabbit holes are left out of the publication.
- The greater the financial and other interests and prejudices in a scientific field, the less likely the research findings are to be true
- This is a huge problem with commercially-oriented research, as the difference between clinical approval for a therapeutic can mean billions of dollars of enterprise value, and the difference between statistically significant and spurious findings for an investment factor can mean billions of dollars of assets under management. Incentives are extremely important in determining bias.
- The hotter a scientific field (with more scientific teams involved), the less likely the research findings are to be true
- This is largely driven by competition, as gold rush fields (such as AI currently) lead to a race to be first. That leads to corner cutting and ultimate disappointment. Ioannidis highlights a fascinating term called the Proteus phenomenon wherein early studies in novel areas are often contradicted at extreme levels.
Now that we’ve highlighted some issues, in Part 2 we will apply this framework of decomposition to the field of quantitative finance, with a focus on what we can do to avoid these pitfalls.
—
The information contained on this site was obtained from various sources that Epsilon believes to be reliable, but Epsilon does not guarantee its accuracy or completeness. The information and opinions contained on this site are subject to change without notice.
Neither the information nor any opinion contained on this site constitutes an offer, or a solicitation of an offer, to buy or sell any securities or other financial instruments, including any securities mentioned in any report available on this site.
The information contained on this site has been prepared and circulated for general information only and is not intended to and does not provide a recommendation with respect to any security. The information on this site does not take into account the financial position or particular needs or investment objectives of any individual or entity. Investors must make their own determinations of the appropriateness of an investment strategy and an investment in any particular securities based upon the legal, tax and accounting considerations applicable to such investors and their own investment objectives. Investors are cautioned that statements regarding future prospects may not be realized and that past performance is not necessarily indicative of future performance.